Dirbtinio intelekto gebėjimų vertinimas
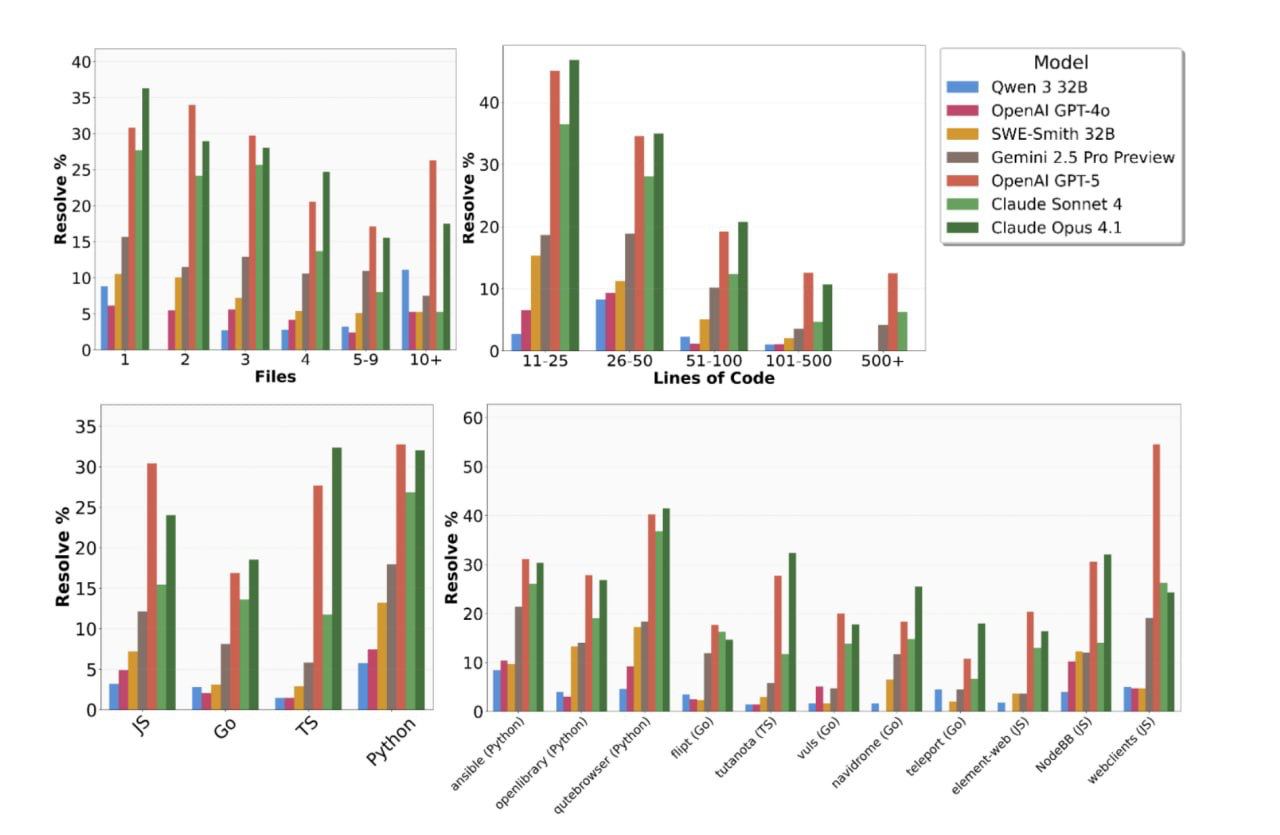
Kompanija Scale AI pristatė naują įrankį SWE-BENCH PRO, skirtą įvertinti dirbtinio intelekto agentų gebėjimus realioje programavimo aplinkoje. Šis bandomasis rinkinys apima beveik 1900 užduočių iš 41 skirtingo kodo saugyklos, o tipinė užduotis reikalauja atlikti pakeitimus šimtuose kodo eilučių ir keliuose failuose.
Rezultatų analizė
Rezultatai parodė, kad net pažangiausi modeliai, tokie kaip GPT-5 ir Claude Opus 4.1, sugebėjo išspręsti tik 18–23% užduočių iš pirmo karto. Geriausią pasirodymą dirbtinis intelektas pademonstravo dirbdamas su Python ir Go programavimo kalbomis, o prasčiausi rezultatai buvo pastebėti naudojant JavaScript ir TypeScript.
Palyginimas su ankstesniais testais
Šie rezultatai atrodo kuklūs, ypač palyginus su ankstesniais testais, kur sėkmės rodiklis siekė iki 70%. Šis skirtumas pabrėžia sudėtingumą ir iššūkius, su kuriais susiduria dirbtinis intelektas bandydamas prisitaikyti prie realių programavimo užduočių.
Išvados
Nors dabartiniai dirbtinio intelekto pasiekimai programavimo srityje dar toli gražu nėra tobuli, jie rodo potencialą ir galimybes tobulėti. Tikėtina, kad ateityje šios technologijos taps dar efektyvesnės ir platesnio pritaikymo, tačiau kol kas jos vis dar mokosi žengti pirmuosius žingsnius tikroje programavimo aplinkoje.