Google TurboQuant: naujas AI atminties naudojimo sprendimas
ICLR 2026 konferencijoje Google Research pristatė TurboQuant – naują dviejų etapų suspaudimo metodą, kuris gali sumažinti transformerių KV atminties naudojimą net iki 40–60% be poreikio iš naujo mokyti modelius ir su minimalia įtaka modelio kokybei.
KV atminties iššūkiai
KV atmintis, sauganti informaciją apie kiekvieną apdorotą žodį pokalbio ar dokumento metu, tapo vienu didžiausių kliūčių modernių didelių kalbos modelių (LLM) veikime. Kai konteksto langai išsiplėtė nuo tūkstančių iki milijonų žodžių, KV atmintis dažnai pradėjo naudoti daugiau GPU atminties nei patys modelio svoriai.
TurboQuant sprendimas
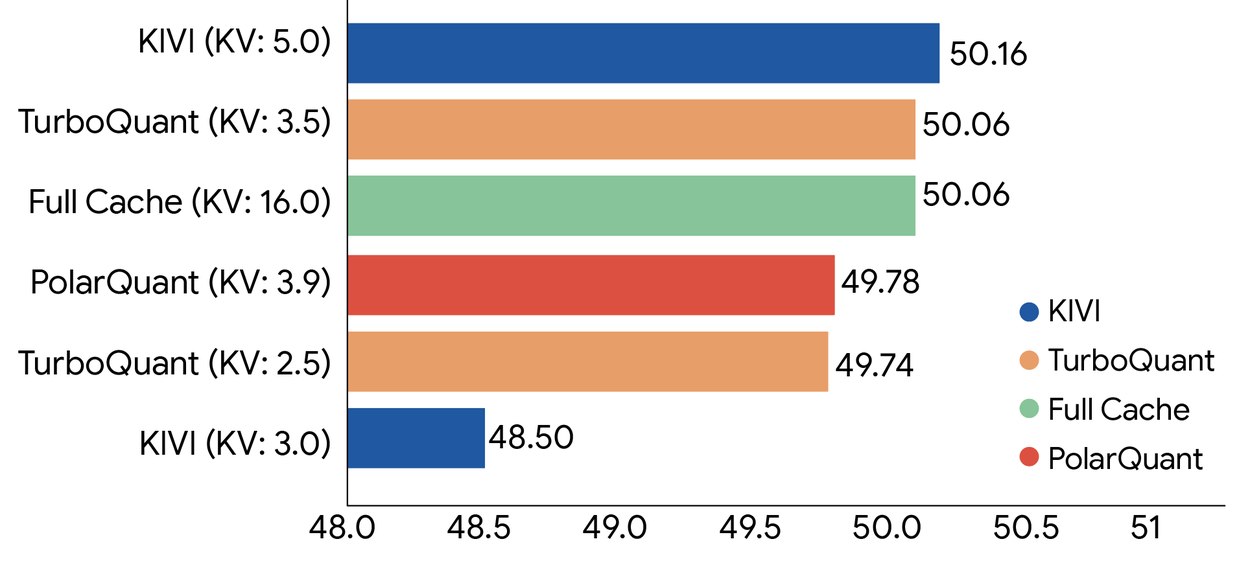
TurboQuant tiesiogiai sprendžia šią problemą. Pirmasis etapas, vadinamas PolarQuant, transformuoja išsaugotus vektorius į formą, kuri labiau tinka kvantizacijai. Antrasis etapas naudoja kvantizuotą Johnson–Lindenstrauss projekciją, kad suspaustų likusį klaidos signalą iki vos vieno bito vienam matmeniui. Šios technikos kartu sumažina KV atminties saugojimo reikalavimus iki maždaug 3–4 bitų vienam elementui.
Reikšmingos pasekmės
Mažesnis atminties naudojimas reiškia daugiau vienu metu veikiančių vartotojų vienam GPU, didesnius konteksto langus ir mažesnes veikimo išlaidas, nekeičiant pagrindinio modelio. Pasaulyje, kuriame AI infrastruktūros išlaidos auga beprecedenčiu tempu, efektyvumo patobulinimai gali būti tokie pat vertingi kaip ir modelio galimybių patobulinimai.
Pramonės tendencijos
Pastaraisiais metais geresnių AI sprendimų atsakymas buvo didesni modeliai, didesnės duomenų bazės ir daugiau skaičiavimų. TurboQuant yra dalis augančios tendencijos, rodančios, kad algoritminis efektyvumas gali atnešti didžiausius laimėjimus ateityje.
Infrastruktūros reikšmė
Modelių kokybė vis labiau vienodėja tarp pirmaujančių AI laboratorijų. Kita konkurencinė pranašumo sritis gali būti šių modelių aptarnavimas greičiau, pigiau ir didesniu mastu. Tokios technikos kaip TurboQuant tiesiogiai taikosi į vieną iš brangiausių didelio masto veikimo komponentų – atmintį.
Reikšmė pramonės ateičiai
Jei efektyvumo orientuotos inovacijos ir toliau duos reikšmingų laimėjimų, 2026 metai gali būti prisimenami kaip metai, kai AI pramonė pradėjo skirti daugiau dėmesio išteklių efektyvumui, o ne modelio dydžiui.